1. Summarizing raw data:
-Numerical: %, averages, frequency tables…
-Graphical: visual representation of data
Relative frequency: frequency of x / total number of responses (e.g., n% of respondents did x).
2. Central Limit Theorem: If taking an infinite number of samples from a given population, the means of these samples would be normally distributed.
Normal curve: perfectly symmetrical about the mean.
The tails are asymptotic (If you look at the graph close enough, you would see the tails never touch the axis).

3. Central Tendnecy: Mean, median, mode
-Mean: The average of all numbers; affected by extreme values (“Outliers”)
-Median: The middle value in ordered sequence (Odd n, middle value; Even n, average of 2 middle values); not affected by extreme values
-Mode: The most frequent value; might have none, one, or several; not affected by extreme values

4. Indexes of Variability: Variance; Standard deviation
Why is Standard Deviation useful?
-SD is a meaningful unit
-Can calculate Confidence Intervals
-Locates a score within a distribution
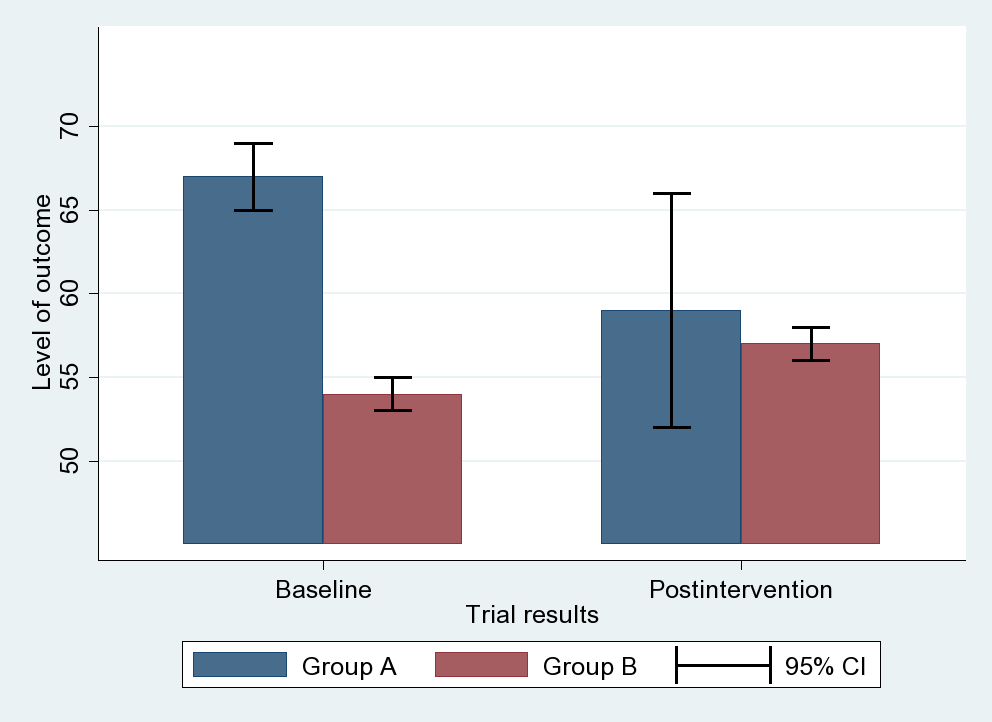
Confidence Intervals: Range of values for which a sample would have if they were to fall close to the mean of the population, with a probability of x%. In other words, you can be x% (normally we use 95%) certain that this range would contain the true mean of the population.
e.g. We calculate CI for 100 times, there should be 95 times that the range calculated would contain the true mean of the population.
Shown as the box-plot lines on bar graphs (example).
5. Z-scores: a way to standardize your data; allow easy comparisions between participants, and between other z-scored measurements; answers the probability of getting a particular value from a normal distribution.

Z distribution has a mean of 0 and SD of 1. “z = -1” means “1 standard deviation away from the mean, in the negative direction”.
















{kind=link}